VectorTraits
English | Chinese(中文)
VectorTraits: SIMD Vector type traits methods (SIMD向量类型的特征方法).
This library provides many important arithmetic methods(e.g. Shift, Shuffle, NarrowSaturate) and constants for vector types, making it easier for you to write cross-platform SIMD code. It takes full advantage of the X86 and Arm architectures' intrinsic functions to achieve hardware acceleration and can enjoy inline compilation optimization.
Commonly Used Types:
Vectors: For vector types, common tool functions are provided, e.g. Create(T/T[]/Span/ReadOnlySpan), CreatePadding, CreateRotate, CreateByFunc, CreateByDouble ... It also provides traits methods for vectors, e.g. ShiftLeft、ShiftRightArithmetic、ShiftRightLogical、Shuffle ...Vectors<T>: For vector types, constants are provided for various element types. e.g. Serial, SerialDesc, XyzwWMask, MantissaMask, MaxValue, MinValue, NormOne, FixedOne, E, Pi, Tau, VMaxByte, VReciprocalMaxSByte ...Vector64s/Vector128s/Vector256s/Vector512s: Common tool functions and traits methods are provided for vectors of fixed bit width (Vector64/Vector128/Vector256/Vector512).Vector64s<T>/Vector128s<T>/Vector256s<T>/Vector512s<T>: Provides constants of various element types for vectors of fixed bit width.Scalars: For scalar types, various tool functions are provided. e.g. GetByDouble, GetFixedByDouble, GetByBits, GetBitsMask ...Scalars<T>: For scalar types, a number of constants are provided. e.g. ExponentBits, MantissaBits, MantissaMask, MaxValue, MinValue, NormOne, FixedOne, E, Pi, Tau, VMaxByte, VReciprocalMaxSByte ...VectorTextUtil: Provides some textual instrumental functions for vectors. e.g. GetHex, Format, WriteLine ...
Traits methods:
- Support for
.NET Standard 2.1new vector methods: ConvertToDouble, ConvertToInt32, ConvertToInt64, ConvertToSingle, ConvertToUInt32, ConvertToUInt64, Narrow, Widen . - Support for
.NET 5.0new vector methods: Ceiling, Floor . - Support for
.NET 6.0new vector methods: Sum . - Support for
.NET 7.0new vector methods: ExtractMostSignificantBits, Shuffle, ShiftLeft, ShiftRightArithmetic, ShiftRightLogical . - Support for
.NET 8.0new vector methods: WidenLower, WidenUpper. - Provides the vector methods of narrow saturate: YNarrowSaturate, YNarrowSaturateUnsigned .
- Provides the vector methods of round: YRoundToEven, YRoundToZero .
- Provides the vector methods of shuffle: YShuffleInsert, YShuffleKernel, YShuffleG2, YShuffleG4, YShuffleG4X2 . Also provides ShuffleControlG2/ShuffleControlG4 enum.
- Provides vector methods for de-interleave: YGroup2Unzip, YGroup2UnzipEven, YGroup2UnzipOdd, YGroup3Unzip, YGroup3UnzipX2, YGroup4Unzip, YGroup6Unzip_Bit128.
- Provides vector methods for interleave: YGroup2Zip, YGroup2ZipHigh, YGroup2ZipLow, YGroup3Zip, YGroup3ZipX2, YGroup4Unzip, YGroup6Zip_Bit128.
- ...
- Full list: TraitsMethodList
Supported instruction set:
- x86 (Need .NET Core 3.0+)
- 128-bit vector: Sse, Sse2, Sse3, Ssse3, Sse41, Sse42. And 128-bit instructions from Avx family.
- 256-bit vector: Avx, Avx2. And 256-bit instructions from Avx512VL.
- 512-bit vector: Avx512BW, Avx512DQ, Avx512F, Avx512Vbmi.
- Arm (Need .NET 5.0+)
- 128-bit vector: AdvSimd.
- Wasm (Need .NET 8.0+)
- 128-bit vector: PackedSimd.
Purpose
The SIMD instruction set is known to accelerate multimedia processing (graphics, images, audio, video, ...) , artificial intelligence, scientific computing, etc. However, traditional SIMD programming suffers from the following pain points.
- Difficult to cross-platform. Because different CPU systems provide different SIMD instruction sets, for example, there are many differences between the SIMD instruction sets of X86 and Arm platforms. If you want to port the program to another platform, you need to find the SIMD instruction set manual of that platform and develop it again.
- Bit widths are difficult to upgrade. Even for the same platform, as it evolves, instruction sets with wider bit widths are gradually added. For example, the X86 platform, in addition to the obsolete 64-bit MMX series instructions, provides a 128-bit SSE instruction set, a 256-bit AVX instruction set, and some high-end processors are starting to support the 512-bit AVX-512 instruction set. Algorithms previously written with 128-bit SSE series instructions need to be redeveloped to take full advantage of the wider SIMD instruction set if they are to be ported to the 256-bit AVX instruction set.
- Poor code readability and high development threshold. Many modern C compilers map
Intrinsic Functionsfor SIMD instructions, which is much easier and more readable than writing assembly code. However, due to the use of some obscure abbreviations for function names, and the fact that C does not support function name overloading, as well as the complexity of the C language itself, there is still a high threshold for code readability and development difficulty.
NET Core 1.0 in 2016 added vector types such as Vector<T>, which largely solves the above pain points.
- Easy cross-platform. NET platform is run by JIT (Just-In-Time Compiler). Only one set of algorithms based on vector methods is written and compiled into only one set of programs. When that program is subsequently run on a different platform, the vector method is compiled by JIT into a platform-specific SIMD instruction set, thus taking full advantage of hardware acceleration.
- Bitwidth can be upgraded automatically. For the
Vector<T>type, its length is not fixed, but is the same as the longest vector register for that processor. Specifically, if the CPU supports the AVX instruction set (strictly AVX2 and above), theVector<T>type is 256 bits; if the CPU only supports the SSE instruction set (strictly SSE2 and above), theVector<T>type is 128 bits. Simply put, you can write your program using only theVector<T>type, and when the program runs, JIT will automatically use the widest SIMD instruction set. - The code is more readable and lowers the development threshold.
.NETplatform, the method names of vector types are composed of complete English words, and make full use of C# syntax features such as function name overloading, so that these method names are both concise and clear. The readability of the code has been greatly improved.
The vector type Vector<T> although well designed, it lacks many important vector functions such as Ceiling, Sum, Shift, Shuffle, etc. This led to many algorithms that were difficult to implement with vector types.
When .NET platform versions are upgraded, sometimes several vector methods are added. .NET 7.0 released in 2022, for example, added ShiftRightArithmetic, Shuffle and other methods. However, there are still few vector methods, such as the lack of saturation processing.
To address the lack of vector methods, .NET Core 3.0 starts to support intrinsic functions. This allows developers to use the SIMD instruction set directly, but again, this faces problems such as difficulty in cross-platform and bit-width upgrades. As the .NET platform is upgraded, more intrinsic functions will be added. For example, .NET 5.0 adds intrinsic functions for the Arm platform.
For developing libraries, you can't just support .NET 7.0, but you need to support multiple .NET versions. So you will face tedious version checking and conditional processing. And the highest version of the .NET Standard class library (2.1) still does not support vector methods like Ceiling, which makes version checking even more tedious.
This library is dedicated to solve the above troubles, so that you can write cross-platform SIMD algorithms more easily. Feature:
- Support for low versions of
.NETprograms (.NET Standard 1.1,.NET Core 1.0,.NET Framework 4.5, ...). Enables low version of.NETprograms to use the latest vector functions. For example, ShiftRightArithmetic, Shuffle, etc. are new in.NET 7.0. - Powerful functions . In addition to referencing vector methods from higher versions of
.NET, this library also provides many useful vector methods by referring to intrinsic functions. e.g. ShiftLeft_Fast, YNarrowSaturate ... - High performance. This library can take full advantage of the X86 and Arm architecture's intrinsic functions for hardware acceleration of vector type computations, and can enjoy inline compilation optimization. This library solves the problem that some of BCL's vector methods (e.g. Multiply, Shuffle, etc.) are not hardware-accelerated on some platforms, because it supplements the hardware-accelerated algorithms.
- Software algorithms are also fast. If you find a method of vector type does not support hardware acceleration,
.NET Bclwill switch to software algorithm, but many of its software algorithms contain branching statements, so the performance is poor. The software algorithm of this library is a highly optimized branchless algorithm. - Easy to use. This library supports not only
Vector<T>, but alsoVector128<T>/Vector256<T>and other vector types. The class name of the tool class is easy to remember (Vectors/Vector64s/Vector128s/Vector256s) and provides many common vector constants through a generic class of the same name. - For each traits method, some properties are added to obtain information. e.g.
_AcceleratedTypes,_FullAcceleratedTypes.
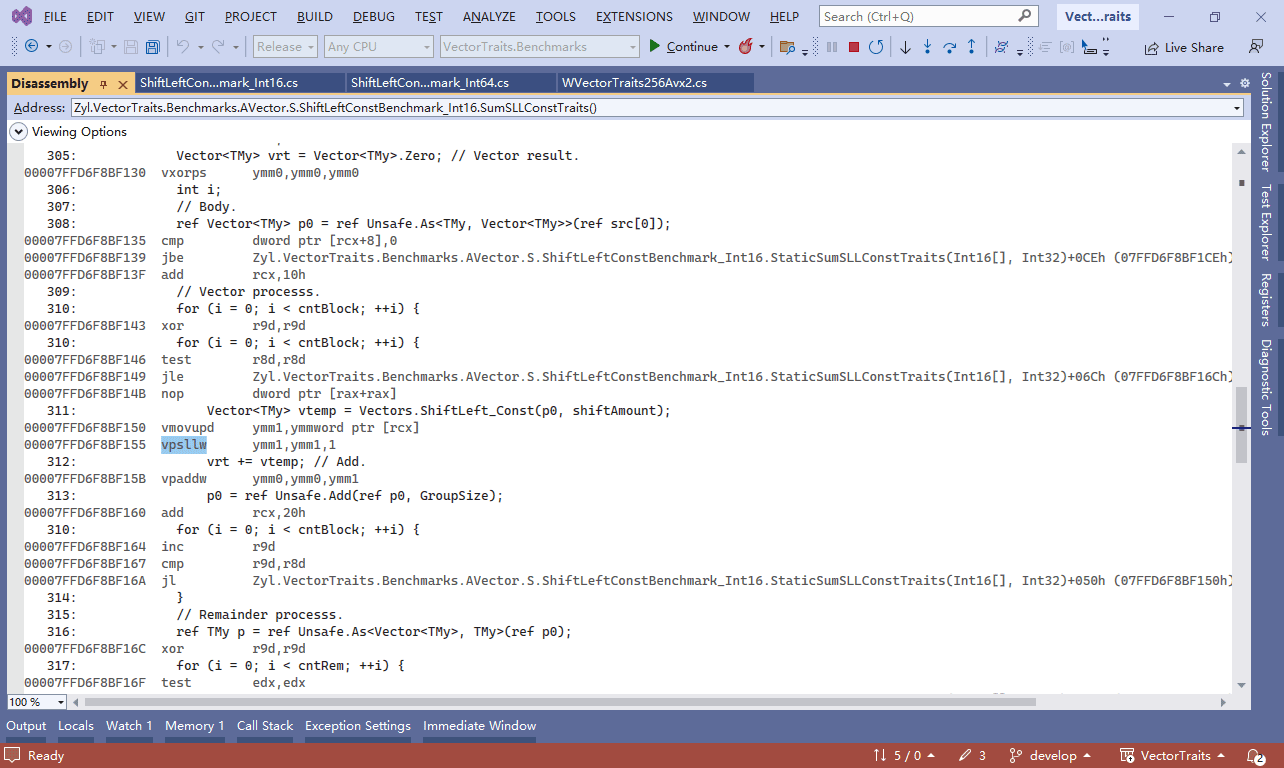
Tip: The Disassembly window in Visual Studio allows you to view the assembly code at runtime. For example, when running on a machine that supports the Avx instruction set, Vectors.ShiftLeft_Const will be compiled inline and optimized to use the vpsllw instruction. And for constant value(1), it will be compiled as the immediate number of the instruction.
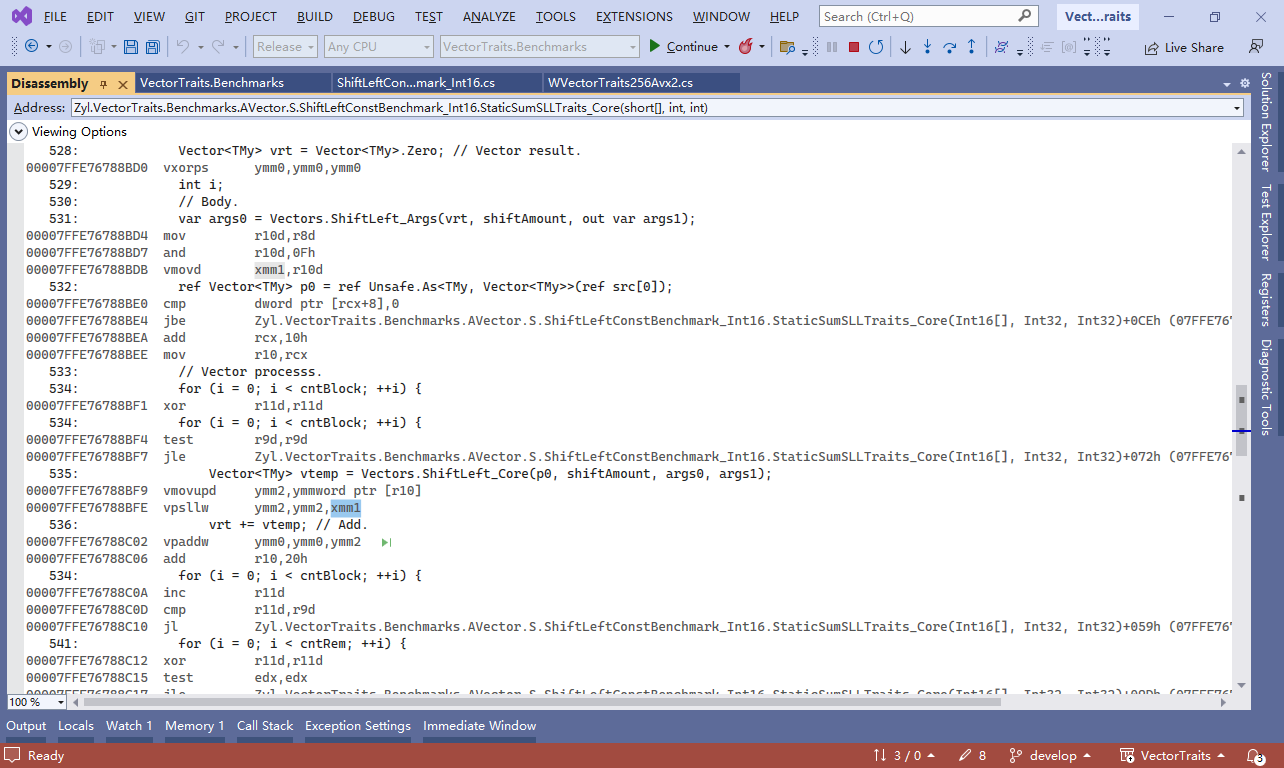
Example 2: Using Vectors.ShiftLeft_Args and Vectors.ShiftLeft_Core, you can move some of the operations outside the loop to be processed earlier. For example, when running on a machine that supports the Avx instruction set, xmm1 is set outside the loop, and then used it in the vpsllw instruction of the inner loop. And here it is shown: the inline compilation optimization eliminates redundant xmm/ymm conversions.
Getting started
1) Install via NuGet
Either open the 'Package Management Console' and enter the following or use the built-in GUI
NuGet: PM> Install-Package VectorTraits
2) Usage examples
The static class Vectors provides some methods. e.g. CreateRotate, ShiftLeft, Shuffle.
The generic structure 'Vectors
The example code is in the samples/VectorTraits.Sample folder. The source code is as follows.
using System;
using System.IO;
using System.Numerics;
#if NETCOREAPP3_0_OR_GREATER
using System.Runtime.Intrinsics;
#endif
using Zyl.VectorTraits;
namespace Zyl.VectorTraits.Sample {
class Program {
private static readonly TextWriter writer = Console.Out;
static void Main(string[] args) {
writer.WriteLine("VectorTraits.Sample");
writer.WriteLine();
VectorTraitsGlobal.Init(); // Initialization .
TraitsOutput.OutputEnvironment(writer); // Output environment info. It depends on `VectorTraits.InfoInc`. This row can be deleted when only VectorTraits are used.
writer.WriteLine();
// -- Start --
Vector<short> src = Vectors.CreateRotate<short>(0, 1, 2, 3, 4, 5, 6, 7); // The `Vectors` class provides some methods. For example, 'CreateRotate' is rotate fill .
VectorTextUtil.WriteLine(writer, "src:\t{0}", src); // It can not only format the string, but also display the hexadecimal of each element in the vector on the right Easy to view vector data .
// ShiftLeft. It is a new vector method in `.NET 7.0`
const int shiftAmount = 1;
Vector<short> shifted = Vectors.ShiftLeft(src, shiftAmount); // shifted[i] = src[i] << shiftAmount.
VectorTextUtil.WriteLine(writer, "ShiftLeft:\t{0}", shifted);
#if NET7_0_OR_GREATER
// Compare BCL function .
Vector<short> shiftedBCL = Vector.ShiftLeft(src, shiftAmount);
VectorTextUtil.WriteLine(writer, "Equals to BCL ShiftLeft:\t{0}", shifted.Equals(shiftedBCL));
#endif
// ShiftLeft_Const
VectorTextUtil.WriteLine(writer, "Equals to ShiftLeft_Const:\t{0}", shifted.Equals(Vectors.ShiftLeft_Const(src, shiftAmount))); // If the parameter shiftAmount is a constant, you can also use the Vectors' ShiftLeft_Const method. It is faster in many scenarios .
writer.WriteLine();
// Shuffle. It is a new vector method in `.NET 7.0`
Vector<short> desc = Vectors<short>.SerialDesc; // The generic structure 'Vectors<T>' provides fields for commonly used constants. For example, 'SerialDesc' is a descending order value .
VectorTextUtil.WriteLine(writer, "desc:\t{0}", desc);
Vector<short> dst = Vectors.Shuffle(shifted, desc); // dst[i] = shifted[desc[i]].
VectorTextUtil.WriteLine(writer, "Shuffle:\t{0}", dst);
#if NET7_0_OR_GREATER
// Compare BCL function .
Vector<short> dstBCL = default; // Since `.NET 7.0`, the Shuffle method has been provided in Vector128/Vector256, but the Shuffle method has not yet been provided in Vector .
if (Vector<short>.Count == Vector128<short>.Count) {
dstBCL = Vector128.Shuffle(shifted.AsVector128(), desc.AsVector128()).AsVector();
} else if (Vector<short>.Count == Vector256<short>.Count) {
dstBCL = Vector256.Shuffle(shifted.AsVector256(), desc.AsVector256()).AsVector();
}
VectorTextUtil.WriteLine(writer, "Equals to BCL Shuffle:\t{0}", dst.Equals(dstBCL));
#endif
// Shuffle_Args and Shuffle_Core
Vectors.Shuffle_Args(desc, out var args0, out var args1); // The suffix is the `Args' method used for parameter calculation, which involves processing such as parameter transformation in advance It is suitable for external loop .
Vector<short> dst2 = Vectors.Shuffle_Core(shifted, args0, args1); // The suffix is the `Core` method used for core calculations, which calculates based on cached parameters It is suitable for internal loop to improve performance .
VectorTextUtil.WriteLine(writer, "Equals to Shuffle_Core:\t{0}", dst.Equals(dst2));
writer.WriteLine();
// Show AcceleratedTypes.
VectorTextUtil.WriteLine(writer, "ShiftLeft_AcceleratedTypes:\t{0}", Vectors.ShiftLeft_AcceleratedTypes);
VectorTextUtil.WriteLine(writer, "Shuffle_AcceleratedTypes:\t{0}", Vectors.Shuffle_AcceleratedTypes);
}
}
}
3) Example results
.NET8.0 on X86
Program: VectorTraits.Sample
VectorTraits.Sample
IsRelease: True
Environment.ProcessorCount: 16
Environment.Is64BitProcess: True
Environment.OSVersion: Microsoft Windows NT 10.0.22631.0
Environment.Version: 8.0.8
Stopwatch.Frequency: 10000000
RuntimeEnvironment.GetRuntimeDirectory: C:\Program Files\dotnet\shared\Microsoft.NETCore.App\8.0.8\
RuntimeInformation.FrameworkDescription: .NET 8.0.8
RuntimeInformation.OSArchitecture: X64
RuntimeInformation.OSDescription: Microsoft Windows 10.0.22631
RuntimeInformation.RuntimeIdentifier: win-x64
IntPtr.Size: 8
BitConverter.IsLittleEndian: True
Vector.IsHardwareAccelerated: True
Vector<byte>.Count: 32 # 256bit
Vector<float>.Count: 8 # 256bit
Vector128.IsHardwareAccelerated: True
Vector256.IsHardwareAccelerated: True
Vector512.IsHardwareAccelerated: True
Vector<T>.Assembly.CodeBase: file:///C:/Program Files/dotnet/shared/Microsoft.NETCore.App/8.0.8/System.Private.CoreLib.dll
GetTargetFrameworkDisplayName(VectorTextUtil): .NET 8.0
GetTargetFrameworkDisplayName(TraitsOutput): .NET 8.0
VectorTraitsGlobal.InitCheckSum: -2122844161 # 0x8177F7FF
VectorEnvironment.CpuModelName: AMD Ryzen 7 7840H w/ Radeon 780M Graphics
VectorEnvironment.SupportedInstructionSets: Aes, Avx, Avx2, Avx512BW, Avx512CD, Avx512DQ, Avx512F, Avx512Vbmi, Avx512VL, Bmi1, Bmi2, Fma, Lzcnt, Pclmulqdq, Popcnt, Sse, Sse2, Sse3, Ssse3, Sse41, Sse42, X86Base
Vector128s.Instance: WVectorTraits128Avx2 // Sse, Sse2, Sse3, Ssse3, Sse41, Sse42, Avx, Avx2, Avx512VL
Vector256s.Instance: WVectorTraits256Avx2 // Avx, Avx2, Sse, Sse2, Avx512VL
Vector512s.Instance: WVectorTraits512Avx512 // Avx512BW, Avx512DQ, Avx512F, Avx512Vbmi, Avx, Avx2, Sse, Sse2
Vectors.Instance: VectorTraits256Avx2 // Avx, Avx2, Sse, Sse2, Avx512VL
Vectors.BaseInstance: VectorTraits256Base
src: <0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7> # (0000 0001 0002 0003 0004 0005 0006 0007 0000 0001 0002 0003 0004 0005 0006 0007)
ShiftLeft: <0, 2, 4, 6, 8, 10, 12, 14, 0, 2, 4, 6, 8, 10, 12, 14> # (0000 0002 0004 0006 0008 000A 000C 000E 0000 0002 0004 0006 0008 000A 000C 000E)
Equals to BCL ShiftLeft: True
Equals to ShiftLeft_Const: True
desc: <15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0> # (000F 000E 000D 000C 000B 000A 0009 0008 0007 0006 0005 0004 0003 0002 0001 0000)
Shuffle: <14, 12, 10, 8, 6, 4, 2, 0, 14, 12, 10, 8, 6, 4, 2, 0> # (000E 000C 000A 0008 0006 0004 0002 0000 000E 000C 000A 0008 0006 0004 0002 0000)
Equals to BCL Shuffle: True
Equals to Shuffle_Core: True
ShiftLeft_AcceleratedTypes: SByte, Byte, Int16, UInt16, Int32, UInt32, Int64, UInt64 # (00001FE0)
Shuffle_AcceleratedTypes: SByte, Byte, Int16, UInt16, Int32, UInt32, Int64, UInt64, Single, Double # (00007FE0)
Note: The text before Vectors.BaseInstance is the environment information output by TraitsOutput.OutputEnvironment. OutputEnvironment. The text starting from srcis the main code of the example. Since the CPU supports the X86 Avx2 instruction set,Vectoris 32(256bit), andVectors.InstanceisVectorTraits256Avx2`.
.NET8.0 on Arm
Program: VectorTraits.Sample
VectorTraits.Sample
IsRelease: True
Environment.ProcessorCount: 2
Environment.Is64BitProcess: True
Environment.OSVersion: Unix 6.8.0.1015
Environment.Version: 8.0.7
Stopwatch.Frequency: 1000000000
RuntimeEnvironment.GetRuntimeDirectory: /home/ubuntu/.dotnet/shared/Microsoft.NETCore.App/8.0.7/
RuntimeInformation.FrameworkDescription: .NET 8.0.7
RuntimeInformation.OSArchitecture: Arm64
RuntimeInformation.OSDescription: Ubuntu 22.04.2 LTS
RuntimeInformation.RuntimeIdentifier: linux-arm64
IntPtr.Size: 8
BitConverter.IsLittleEndian: True
Vector.IsHardwareAccelerated: True
Vector<byte>.Count: 16 # 128bit
Vector<float>.Count: 4 # 128bit
Vector128.IsHardwareAccelerated: True
Vector256.IsHardwareAccelerated: False
Vector512.IsHardwareAccelerated: False
Vector<T>.Assembly.CodeBase: file:///home/ubuntu/.dotnet/shared/Microsoft.NETCore.App/8.0.7/System.Private.CoreLib.dll
GetTargetFrameworkDisplayName(VectorTextUtil): .NET 8.0
GetTargetFrameworkDisplayName(TraitsOutput): .NET 8.0
VectorTraitsGlobal.InitCheckSum: -2122844159 # 0x8177F801
VectorEnvironment.CpuModelName: Neoverse-N1
VectorEnvironment.CpuFlags: fp asimd evtstrm aes pmull sha1 sha2 crc32 atomics fphp asimdhp cpuid asimdrdm lrcpc dcpop asimddp ssbs
VectorEnvironment.SupportedInstructionSets: AdvSimd, Aes, ArmBase, Crc32, Dp, Rdm, Sha1, Sha256
Vector128s.Instance: WVectorTraits128AdvSimdB64 // AdvSimd
Vectors.Instance: VectorTraits128AdvSimdB64 // AdvSimd
Vectors.BaseInstance: VectorTraits128Base
src: <0, 1, 2, 3, 4, 5, 6, 7> # (0000 0001 0002 0003 0004 0005 0006 0007)
ShiftLeft: <0, 2, 4, 6, 8, 10, 12, 14> # (0000 0002 0004 0006 0008 000A 000C 000E)
Equals to BCL ShiftLeft: True
Equals to ShiftLeft_Const: True
desc: <7, 6, 5, 4, 3, 2, 1, 0> # (0007 0006 0005 0004 0003 0002 0001 0000)
Shuffle: <14, 12, 10, 8, 6, 4, 2, 0> # (000E 000C 000A 0008 0006 0004 0002 0000)
Equals to BCL Shuffle: True
Equals to Shuffle_Core: True
ShiftLeft_AcceleratedTypes: SByte, Byte, Int16, UInt16, Int32, UInt32, Int64, UInt64 # (00001FE0)
Shuffle_AcceleratedTypes: SByte, Byte, Int16, UInt16, Int32, UInt32, Int64, UInt64, Single, Double # (00007FE0)
The result is the same as the X86 one, only the environment information is different.
Since the CPU supports Arm's AdvSimd instruction set, Vector<byte>.Count is 16(128bit) and Vectors.Instance is VectorTraits128AdvSimdB64.
.NET Framework 4.5 on X86
Program: VectorTraits.Sample.NetFw.
VectorTraits.Sample
IsRelease: True
Environment.ProcessorCount: 16
Environment.Is64BitProcess: True
Environment.OSVersion: Microsoft Windows NT 6.2.9200.0
Environment.Version: 4.0.30319.42000
Stopwatch.Frequency: 10000000
RuntimeEnvironment.GetRuntimeDirectory: C:\Windows\Microsoft.NET\Framework64\v4.0.30319\
RuntimeInformation.FrameworkDescription: .NET Framework 4.8.9277.0
RuntimeInformation.OSArchitecture: X64
RuntimeInformation.OSDescription: Microsoft Windows 10.0.22631
IntPtr.Size: 8
BitConverter.IsLittleEndian: True
Vector.IsHardwareAccelerated: True
Vector<byte>.Count: 32 # 256bit
Vector<float>.Count: 8 # 256bit
Vector<T>.Assembly.CodeBase: file:///E:/zylSelf/Code/cs/base/VectorTraits/tests/VectorTraits.Benchmarks.NetFw/bin/Release/System.Numerics.Vectors.DLL
GetTargetFrameworkDisplayName(VectorTextUtil): .NET Standard 1.1
GetTargetFrameworkDisplayName(TraitsOutput): .NET Framework 4.5
VectorTraitsGlobal.InitCheckSum: -25396097 # 0xFE7C7C7F
VectorEnvironment.CpuModelName: AMD Ryzen 7 7840H w/ Radeon 780M Graphics
VectorEnvironment.SupportedInstructionSets:
Vectors.Instance: VectorTraits256Base //
Vectors.BaseInstance: VectorTraits256Base
src: <0, 1, 2, 3, 4, 5, 6, 7, 0, 1, 2, 3, 4, 5, 6, 7> # (0000 0001 0002 0003 0004 0005 0006 0007 0000 0001 0002 0003 0004 0005 0006 0007)
ShiftLeft: <0, 2, 4, 6, 8, 10, 12, 14, 0, 2, 4, 6, 8, 10, 12, 14> # (0000 0002 0004 0006 0008 000A 000C 000E 0000 0002 0004 0006 0008 000A 000C 000E)
Equals to ShiftLeft_Const: True
desc: <15, 14, 13, 12, 11, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 0> # (000F 000E 000D 000C 000B 000A 0009 0008 0007 0006 0005 0004 0003 0002 0001 0000)
Shuffle: <14, 12, 10, 8, 6, 4, 2, 0, 14, 12, 10, 8, 6, 4, 2, 0> # (000E 000C 000A 0008 0006 0004 0002 0000 000E 000C 000A 0008 0006 0004 0002 0000)
Equals to Shuffle_Core: True
ShiftLeft_AcceleratedTypes: SByte, Byte, Int16, UInt16, Int32, UInt32 # (000007E0)
Shuffle_AcceleratedTypes: None # (00000000)
ShiftLeft/Shuffle of Vectors works fine.
Since the CPU supports the X86 Avx2 instruction set, Vector<byte>.Count is 32 (256bit). Vectors.InstanceisVectorTraits256Base. It's not VectorTraits256Avx2because the intrinsic function wasn't supported until.NET Core 3.0`.
The value of ShiftLeft_AcceleratedTypes contains types such as "Int16", which means that ShiftLeft is hardware-accelerated when using these types. The library makes clever use of vector algorithms to try to achieve hardware acceleration even without intrinsic functions.
Results of benchmark
Unit of data: Million operations per second. The larger the number, the better the performance.
ShiftLeft
ShiftLeft: Shifts each element of a vector left by the specified amount.
It is a new vector method in .NET 7.0.
ShiftLeft - X86 - AMD Ryzen 7 7840H
| Type | Method | .NET Framework | .NET Core 2.1 | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|---|---|
| Byte | SumSLLScalar | 1062.046 | 1025.936 | 1287.865 | 1265.446 | 1445.575 | 1416.712 | 1693.330 |
| Byte | SumSLLNetBcl | 1344.738 | 1109.752 | |||||
| Byte | SumSLLNetBcl_Const | 1281.901 | 1164.382 | |||||
| Byte | SumSLLTraits | 11312.499 | 10715.920 | 28897.868 | 28611.234 | 28219.205 | 34068.741 | 57456.802 |
| Byte | SumSLLTraits_Core | 55791.675 | 52165.732 | 53563.421 | 68653.359 | 59916.622 | 67868.291 | 74889.177 |
| Byte | SumSLLConstTraits | 13408.916 | 12604.412 | 38925.388 | 57842.081 | 57095.294 | 62012.692 | 62729.225 |
| Byte | SumSLLConstTraits_Core | 56843.523 | 55673.528 | 53642.484 | 62674.397 | 65797.708 | 50869.840 | 73873.979 |
| Int16 | SumSLLScalar | 1081.716 | 999.767 | 1261.475 | 1198.111 | 1218.767 | 1365.754 | 1547.294 |
| Int16 | SumSLLNetBcl | 32011.646 | 34816.284 | |||||
| Int16 | SumSLLNetBcl_Const | 39975.924 | 37368.541 | |||||
| Int16 | SumSLLTraits | 6752.349 | 6185.968 | 25221.856 | 26382.708 | 27125.955 | 32617.944 | 36448.716 |
| Int16 | SumSLLTraits_Core | 34727.283 | 31457.238 | 31800.310 | 32231.553 | 35687.996 | 37750.305 | 30731.745 |
| Int16 | SumSLLConstTraits | 6037.367 | 6498.819 | 27783.526 | 37605.559 | 40699.914 | 39598.663 | 36242.630 |
| Int16 | SumSLLConstTraits_Core | 37678.435 | 34784.616 | 32625.543 | 33694.338 | 40019.325 | 39380.404 | 36914.775 |
| Int32 | SumSLLScalar | 1369.140 | 1315.852 | 1514.690 | 1521.516 | 2284.670 | 2484.407 | 2409.358 |
| Int32 | SumSLLNetBcl | 17373.567 | 15954.004 | |||||
| Int32 | SumSLLNetBcl_Const | 17967.080 | 15983.409 | |||||
| Int32 | SumSLLTraits | 3762.374 | 3511.433 | 13343.304 | 12906.293 | 12661.423 | 17279.760 | 15886.410 |
| Int32 | SumSLLTraits_Core | 17324.275 | 15468.381 | 14587.937 | 17407.823 | 17886.651 | 18052.162 | 14126.571 |
| Int32 | SumSLLConstTraits | 3910.600 | 3724.412 | 12646.545 | 15290.340 | 17745.992 | 17829.078 | 15991.615 |
| Int32 | SumSLLConstTraits_Core | 16235.154 | 14216.598 | 15282.565 | 16088.400 | 17940.330 | 15961.166 | 16378.506 |
| Int64 | SumSLLScalar | 1394.719 | 1281.156 | 1517.938 | 1441.160 | 2270.521 | 2508.577 | 2421.558 |
| Int64 | SumSLLNetBcl | 7528.184 | 8530.835 | |||||
| Int64 | SumSLLNetBcl_Const | 8743.504 | 8471.981 | |||||
| Int64 | SumSLLTraits | 483.430 | 494.335 | 6677.544 | 6570.711 | 6635.070 | 6891.705 | 7469.236 |
| Int64 | SumSLLTraits_Core | 479.761 | 488.827 | 7758.515 | 8525.784 | 8596.290 | 8267.855 | 7879.060 |
| Int64 | SumSLLConstTraits | 509.585 | 525.195 | 7036.223 | 6787.101 | 8246.601 | 8254.880 | 8526.022 |
| Int64 | SumSLLConstTraits_Core | 512.652 | 528.381 | 8229.954 | 8747.125 | 8711.523 | 8871.948 | 8647.339 |
Description.
- SumSLLScalar: Use scalar algorithm.
- SumSLLNetBcl: Use the BCL method (
Vector.ShiftLeft) with variable arguments. Note that this method is only available in.NET 7.0. - SumSLLNetBcl_Const: Use the BCL method (
Vector.ShiftLeft) with constant arguments. Note that this method is only available in.NET 7.0. - SumSLLTraits: Use this library's normal method (
Vectors.ShiftLeft) with variable arguments. - SumSLLTraits_Core: Use this library's
Coresuffixed methods (Vectors.ShiftLeft_Args,Vectors.ShiftLeft_Core) with variable arguments. - SumSLLConstTraits: Use this library's
Constsuffixed method (Vectors.ShiftLeft_Const) with constants arguments. - SumSLLConstTraits_Core: Use this library's
ConstCoresuffixed methods (Vectors.ShiftLeft_Args,Vectors.ShiftLeft_ConstCore) with constant arguments.
BCL's method (Vector.ShiftLeft) runs on X86 platform, only Int16/Int32/Int64 are hardware accelerated, while Byte is not hardware accelerated. This is probably because the Avx2 instruction set only has 16-64 bit left shift instructions, and does not provide other types of instructions, so the BCL is converted to a software algorithm.
For these types of numbers, this library will replace them with efficient algorithms realized by combinations of other instructions. For example, for Byte type, SumSLLConstTraits_Core in . NET 7.0 has the value of 73873.979, which is 73873.979/1693.330≈43.6264 times the performance of scalar algorithm, and 73873.979/1164.382≈63.4448 times the performance of BCL method. 32872.874/1137.564≈28.8976times. Because X86 intrinsic functions have only been available since.NET Core 3.0. Therefore, for Int64 types, hardware acceleration is not available until after .NET Core 3.0`.
For ShiftLeft, when shiftAmount is a constant, the performance is generally better than when it is a variable. This is true for both BCL and this library methods.
Using this library's Core suffix optimizes performance by moving some operations out of the loop to be processed earlier. When the CPU provides instructions with constant parameters (the technical term is "immediate parameters"), the performance of the instructions is generally higher. So the library also provides a ConstCore suffix method, which selects the fastest instruction for that platform.
Sometimes the performance fluctuates due to "CPU Turbo Boost", "other processes taking CPU resources", etc. But rest assured, after checking the assembly instructions of the Release's program runtime, it is already running on the best hardware instructions. An example of this is the following figure.
ShiftLeft - Arm - AWS Arm t4g.small
| Type | Method | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|
| Byte | SumSLLScalar | 606.721 | 607.751 | 674.256 | 890.878 | 1238.814 |
| Byte | SumSLLNetBcl | 19585.982 | 19831.927 | |||
| Byte | SumSLLNetBcl_Const | 19564.840 | 19840.232 | |||
| Byte | SumSLLTraits | 5541.532 | 13075.259 | 13190.705 | 13209.927 | 19844.497 |
| Byte | SumSLLTraits_Core | 14048.511 | 16947.485 | 15828.571 | 19589.430 | 19841.525 |
| Byte | SumSLLConstTraits | 9734.870 | 15699.315 | 15853.772 | 19511.952 | 19811.385 |
| Byte | SumSLLConstTraits_Core | 13007.028 | 16817.247 | 15838.060 | 19422.222 | 19839.627 |
| Int16 | SumSLLScalar | 606.135 | 603.800 | 605.734 | 820.880 | 1031.035 |
| Int16 | SumSLLNetBcl | 9943.220 | 9803.495 | |||
| Int16 | SumSLLNetBcl_Const | 9937.639 | 9837.136 | |||
| Int16 | SumSLLTraits | 4215.369 | 6547.514 | 6558.299 | 9923.088 | 9839.256 |
| Int16 | SumSLLTraits_Core | 7918.688 | 8431.934 | 7892.235 | 9939.469 | 9839.496 |
| Int16 | SumSLLConstTraits | 6568.606 | 7829.860 | 7887.842 | 9925.988 | 9839.534 |
| Int16 | SumSLLConstTraits_Core | 8494.550 | 8416.796 | 7902.444 | 9914.384 | 9823.608 |
| Int32 | SumSLLScalar | 747.656 | 746.013 | 749.108 | 1406.122 | 1410.137 |
| Int32 | SumSLLNetBcl | 4926.651 | 4826.909 | |||
| Int32 | SumSLLNetBcl_Const | 4917.732 | 4840.232 | |||
| Int32 | SumSLLTraits | 3293.943 | 3269.129 | 3278.303 | 4925.488 | 4836.941 |
| Int32 | SumSLLTraits_Core | 4210.811 | 3930.619 | 3927.408 | 4923.867 | 4844.083 |
| Int32 | SumSLLConstTraits | 3275.986 | 3249.809 | 3923.176 | 4926.463 | 4846.238 |
| Int32 | SumSLLConstTraits_Core | 4205.245 | 4199.155 | 4156.634 | 4925.448 | 4844.679 |
| Int64 | SumSLLScalar | 739.137 | 729.158 | 741.673 | 1372.480 | 1296.655 |
| Int64 | SumSLLNetBcl | 2477.025 | 2264.032 | |||
| Int64 | SumSLLNetBcl_Const | 2473.102 | 2251.272 | |||
| Int64 | SumSLLTraits | 486.734 | 1638.835 | 1636.233 | 1985.596 | 2285.512 |
| Int64 | SumSLLTraits_Core | 489.554 | 2075.273 | 1967.902 | 2474.105 | 2289.521 |
| Int64 | SumSLLConstTraits | 467.393 | 1930.821 | 1968.798 | 2471.124 | 2308.745 |
| Int64 | SumSLLConstTraits_Core | 466.293 | 2074.656 | 1968.834 | 2476.602 | 2281.018 |
Description.
- SumSLLScalar: Use scalar algorithm.
- SumSLLNetBcl: Use the BCL method (
Vector.ShiftLeft) with variable arguments. Note that this method is only available in.NET 7.0. - SumSLLNetBcl_Const: Use the BCL method (
Vector.ShiftLeft) with constant arguments. Note that this method is only available in.NET 7.0. - SumSLLTraits: Use this library's normal method (
Vectors.ShiftLeft) with variable arguments. - SumSLLTraits_Core: Use this library's
Coresuffixed methods (Vectors.ShiftLeft_Args,Vectors.ShiftLeft_Core) with variable arguments. - SumSLLConstTraits: Use this library's
Constsuffixed method (Vectors.ShiftLeft_Const) with constants arguments. - SumSLLConstTraits_Core: Use this library's
ConstCoresuffixed methods (Vectors.ShiftLeft_Args,Vectors.ShiftLeft_ConstCore) with constant arguments.
The BCL method (Vector.ShiftLeft) runs on the Arm platform with hardware acceleration for integer types. The AdvSimd instruction set provides special instructions for left shifting of 8 to 64 bit integers.
This library uses the same instructions when running on the Arm platform. The performance is close.
Because Arm's intrinsic functions have only been available since .NET 5.0. The hardware acceleration for Int64 types is not available until after `.NET 5.0'.
ShiftRightArithmetic
ShiftRightArithmetic: Shifts (signed) each element of a vector right by the specified amount.
It is a new vector method in .NET 7.0.
ShiftRightArithmetic - X86 - AMD Ryzen 7 7840H
| Type | Method | .NET Framework | .NET Core 2.1 | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|---|---|
| Int16 | SumSRAScalar | 1085.176 | 1043.731 | 1227.822 | 1215.729 | 1209.230 | 1310.645 | 1397.378 |
| Int16 | SumSRANetBcl | 31888.645 | 35102.079 | |||||
| Int16 | SumSRANetBcl_Const | 39751.018 | 36630.458 | |||||
| Int16 | SumSRATraits | 1829.405 | 1861.938 | 25643.096 | 26584.675 | 26634.093 | 31578.602 | 37184.123 |
| Int16 | SumSRATraits_Core | 1837.663 | 1874.262 | 33248.481 | 36967.972 | 36890.508 | 37648.798 | 37673.670 |
| Int16 | SumSRAConstTraits | 1836.653 | 1880.351 | 28724.613 | 36985.528 | 39429.041 | 32925.588 | 37356.009 |
| Int16 | SumSRAConstTraits_Core | 1830.444 | 1879.354 | 33935.625 | 37498.165 | 38127.794 | 33120.549 | 35752.947 |
| Int32 | SumSRAScalar | 1362.876 | 1321.507 | 1508.831 | 1508.378 | 2226.648 | 2555.622 | 2327.611 |
| Int32 | SumSRANetBcl | 16806.958 | 15967.982 | |||||
| Int32 | SumSRANetBcl_Const | 18365.861 | 16092.208 | |||||
| Int32 | SumSRATraits | 883.925 | 895.137 | 12901.507 | 12508.762 | 11931.480 | 17609.103 | 16282.512 |
| Int32 | SumSRATraits_Core | 919.507 | 931.419 | 15956.786 | 15252.829 | 17412.025 | 18296.493 | 16230.128 |
| Int32 | SumSRAConstTraits | 911.750 | 942.523 | 13450.043 | 17314.816 | 14198.095 | 16799.445 | 16393.351 |
| Int32 | SumSRAConstTraits_Core | 917.228 | 938.789 | 15344.136 | 15470.629 | 17084.816 | 18274.411 | 16054.229 |
| Int32 | SumSRAFastTraits | 915.754 | 946.521 | 13266.168 | 15337.171 | 14562.129 | 17003.224 | 16124.004 |
| Int64 | SumSRAScalar | 1393.540 | 1331.963 | 1532.719 | 1544.306 | 1513.245 | 1801.859 | 2560.284 |
| Int64 | SumSRANetBcl | 524.702 | 8652.579 | |||||
| Int64 | SumSRANetBcl_Const | 557.152 | 8870.207 | |||||
| Int64 | SumSRATraits | 482.604 | 490.804 | 4949.328 | 4970.328 | 4932.277 | 4902.239 | 7541.726 |
| Int64 | SumSRATraits_Core | 509.432 | 521.769 | 5941.547 | 6050.322 | 6104.433 | 6043.337 | 8537.297 |
| Int64 | SumSRAConstTraits | 510.778 | 529.298 | 5526.893 | 5360.460 | 5834.075 | 6217.509 | 7562.071 |
| Int64 | SumSRAConstTraits_Core | 509.597 | 531.344 | 5899.752 | 5978.398 | 6049.756 | 6171.211 | 7720.979 |
| SByte | SumSRAScalar | 997.067 | 974.147 | 1278.049 | 1350.082 | 1227.788 | 1328.380 | 1387.993 |
| SByte | SumSRANetBcl | 1135.177 | 1113.944 | |||||
| SByte | SumSRANetBcl_Const | 1165.780 | 1061.118 | |||||
| SByte | SumSRATraits | 3635.592 | 3696.780 | 24686.302 | 22906.323 | 22437.129 | 24879.962 | 44225.353 |
| SByte | SumSRATraits_Core | 3652.670 | 3743.427 | 41915.608 | 45147.925 | 45375.300 | 46792.941 | 45642.076 |
| SByte | SumSRAConstTraits | 3651.109 | 3753.761 | 29819.076 | 42019.515 | 43095.169 | 44048.300 | 47091.982 |
| SByte | SumSRAConstTraits_Core | 3662.694 | 3753.270 | 39588.701 | 46397.665 | 47507.648 | 43046.477 | 46878.753 |
Description.
- SumSRAScalar: Use scalar algorithm.
- SumSRANetBcl: Use the BCL method (
Vector.ShiftRight) with variable arguments. Note that this method is only available in.NET 7.0. - SumSRANetBcl_Const: Use the BCL method (
Vector.ShiftRight) with constant arguments. Note that this method is only available in.NET 7.0. - SumSRATraits: Use this library's normal method (
Vectors.ShiftRight) with variable arguments. - SumSRATraits_Core: Use this library's
Coresuffixed methods (Vectors.ShiftRight_Args,Vectors.ShiftRight_Core) with variable arguments. - SumSRAConstTraits: Use this library's
Constsuffixed method (Vectors.ShiftRight_Const) with constants arguments. - SumSRAConstTraits_Core: Use this library's
ConstCoresuffixed methods (Vectors.ShiftRight_Args,Vectors.ShiftRight_ConstCore) with constant arguments.
The BCL method (Vector.ShiftRightArithmetic) runs on X86 platforms with hardware acceleration only for Int16/Int32, but not for SByte/Int64. This is probably because the Avx2 instruction set only has 16-32 bit arithmetic right shift instructions. The Avx512 instruction set has added a 64 bit arithmetic right shift instruction.
For these types of numbers, this library replaces them with efficient algorithms that are implemented by a combination of other instructions. As of .NET Core 3.0, hardware acceleration is available.
ShiftRightArithmetic - Arm - AWS Arm t4g.small
| Type | Method | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|
| Int16 | SumSRAScalar | 604.429 | 602.027 | 606.297 | 818.740 | 830.302 |
| Int16 | SumSRANetBcl | 9941.412 | 9837.372 | |||
| Int16 | SumSRANetBcl_Const | 9931.397 | 9838.530 | |||
| Int16 | SumSRATraits | 1713.818 | 5611.316 | 4949.502 | 9932.269 | 9837.893 |
| Int16 | SumSRATraits_Core | 1928.197 | 7881.850 | 8435.043 | 9930.918 | 9707.757 |
| Int16 | SumSRAConstTraits | 1936.057 | 7776.346 | 8432.064 | 9926.348 | 9834.469 |
| Int16 | SumSRAConstTraits_Core | 1895.291 | 7825.036 | 8426.085 | 9923.414 | 9834.395 |
| Int32 | SumSRAScalar | 745.287 | 749.467 | 747.486 | 1181.651 | 1244.019 |
| Int32 | SumSRANetBcl | 4929.438 | 4848.848 | |||
| Int32 | SumSRANetBcl_Const | 4937.824 | 4854.964 | |||
| Int32 | SumSRATraits | 859.173 | 2815.113 | 2819.116 | 4937.562 | 4813.108 |
| Int32 | SumSRATraits_Core | 945.694 | 3917.314 | 3916.943 | 4933.939 | 4787.843 |
| Int32 | SumSRAConstTraits | 967.576 | 3904.750 | 4188.713 | 4901.680 | 4849.051 |
| Int32 | SumSRAConstTraits_Core | 947.955 | 3906.471 | 4192.951 | 4908.354 | 4853.184 |
| Int64 | SumSRAScalar | 738.902 | 734.754 | 741.343 | 1185.217 | 1243.954 |
| Int64 | SumSRANetBcl | 2474.620 | 2433.159 | |||
| Int64 | SumSRANetBcl_Const | 2478.519 | 2438.677 | |||
| Int64 | SumSRATraits | 467.838 | 1233.506 | 1233.401 | 1418.970 | 2424.896 |
| Int64 | SumSRATraits_Core | 468.470 | 1952.967 | 1971.453 | 2478.229 | 2424.819 |
| Int64 | SumSRAConstTraits | 467.182 | 1939.969 | 1970.321 | 2474.340 | 2413.790 |
| Int64 | SumSRAConstTraits_Core | 468.634 | 2095.352 | 2102.958 | 2474.473 | 2432.455 |
| SByte | SumSRAScalar | 608.671 | 609.771 | 652.251 | 889.935 | 830.400 |
| SByte | SumSRANetBcl | 19779.972 | 19615.987 | |||
| SByte | SumSRANetBcl_Const | 19803.799 | 19613.758 | |||
| SByte | SumSRATraits | 3482.537 | 11212.340 | 9894.245 | 11352.199 | 19512.654 |
| SByte | SumSRATraits_Core | 3857.464 | 16756.195 | 15733.712 | 19816.163 | 19419.454 |
| SByte | SumSRAConstTraits | 3905.027 | 15518.199 | 15732.344 | 19791.972 | 19617.529 |
| SByte | SumSRAConstTraits_Core | 3796.018 | 16708.142 | 16787.090 | 19791.891 | 19619.300 |
Description.
- SumSRAScalar: Use scalar algorithm.
- SumSRANetBcl: Use the BCL method (
Vector.ShiftRight) with variable arguments. Note that this method is only available in.NET 7.0. - SumSRANetBcl_Const: Use the BCL method (
Vector.ShiftRight) with constant arguments. Note that this method is only available in.NET 7.0. - SumSRATraits: Use this library's normal method (
Vectors.ShiftRight) with variable arguments. - SumSRATraits_Core: Use this library's
Coresuffixed methods (Vectors.ShiftRight_Args,Vectors.ShiftRight_Core) with variable arguments. - SumSRAConstTraits: Use this library's
Constsuffixed method (Vectors.ShiftRight_Const) with constants arguments. - SumSRAConstTraits_Core: Use this library's
ConstCoresuffixed methods (Vectors.ShiftRight_Args,Vectors.ShiftRight_ConstCore) with constant arguments.
BCL methods (Vector.ShiftRightArithmetic) are hardware accelerated for integer types when running on Arm platforms. The AdvSimd instruction set provides special instructions for arithmetic right shifting of 8 to 64 bit integers.
This library uses the same instructions when running on the Arm platform. The performance is similar. As of .NET 5.0, hardware acceleration is available.
Shuffle
Shuffle: Shuffle and clear. Creates a new vector by selecting values from an input vector using a set of indices.
It is a new vector method in .NET 7.0. Since .NET 7.0, the Shuffle method has been provided in Vector128/Vector256, but the Shuffle method has not yet been provided in Vector.
Shuffle allows an index to exceed the valid range, and then sets the corresponding element to 0. This feature slows down performance a bit, so this library also provides the YShuffleKernel method (Only shuffle). If you want to make sure that the index is always within the valid range, it is faster to use YShuffleKernel.
Shuffle - X86 - AMD Ryzen 7 7840H
| Type | Method | .NET Framework | .NET Core 2.1 | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|---|---|
| Int16 | SumScalar | 1236.944 | 1263.908 | 1214.484 | 1278.657 | 1195.188 | 1408.179 | 1235.365 |
| Int16 | Sum256_Bcl | 1074.656 | 938.447 | |||||
| Int16 | Sum512_Bcl | 918.911 | ||||||
| Int16 | SumTraits | 1221.046 | 1255.341 | 8067.493 | 10943.134 | 10421.696 | 14194.280 | 32579.746 |
| Int16 | SumTraits_Args0 | 1278.650 | 1211.361 | 22661.648 | 25363.988 | 24123.555 | 26722.243 | 34671.910 |
| Int16 | SumTraits_Args | 1255.109 | 1154.801 | 22911.649 | 26138.766 | 24804.170 | 26585.684 | 33172.777 |
| Int16 | SumKernelTraits | 1269.733 | 1192.079 | 8698.117 | 12377.326 | 11972.407 | 17610.477 | 35632.301 |
| Int16 | SumKernelTraits_Args0 | 1297.765 | 1199.697 | 23028.564 | 25852.122 | 25176.482 | 24261.582 | 36741.022 |
| Int16 | SumKernelTraits_Args | 1270.852 | 1142.885 | 23265.595 | 25960.405 | 21744.418 | 23156.078 | 37227.607 |
| Int32 | SumScalar | 850.057 | 829.782 | 816.013 | 859.672 | 817.223 | 853.140 | 837.720 |
| Int32 | Sum256_Bcl | 755.314 | 770.558 | |||||
| Int32 | Sum512_Bcl | 930.330 | ||||||
| Int32 | SumTraits | 821.394 | 844.388 | 10852.534 | 10832.760 | 10943.342 | 12695.692 | 15067.794 |
| Int32 | SumTraits_Args0 | 864.447 | 818.042 | 12704.591 | 15953.127 | 15574.554 | 14391.785 | 15559.766 |
| Int32 | SumTraits_Args | 810.166 | 762.183 | 12531.310 | 14746.991 | 14125.335 | 13524.193 | 15368.528 |
| Int32 | SumKernelTraits | 825.747 | 841.229 | 14515.308 | 14407.190 | 14545.131 | 16276.648 | 15999.993 |
| Int32 | SumKernelTraits_Args0 | 856.015 | 814.055 | 14754.810 | 14880.916 | 17262.390 | 14319.199 | 16261.174 |
| Int32 | SumKernelTraits_Args | 806.479 | 765.218 | 15073.768 | 14604.621 | 16999.007 | 16367.119 | 16422.220 |
| Int64 | SumScalar | 425.474 | 430.216 | 457.179 | 497.203 | 465.105 | 432.348 | 425.921 |
| Int64 | Sum256_Bcl | 506.686 | 515.520 | |||||
| Int64 | Sum512_Bcl | 688.892 | ||||||
| Int64 | SumTraits | 474.906 | 431.296 | 3789.327 | 4192.951 | 4280.568 | 4155.819 | 8171.028 |
| Int64 | SumTraits_Args0 | 423.703 | 461.664 | 6979.885 | 7855.241 | 8501.271 | 7846.303 | 8198.449 |
| Int64 | SumTraits_Args | 446.260 | 420.925 | 6704.874 | 8599.441 | 8317.550 | 7312.362 | 8378.340 |
| Int64 | SumKernelTraits | 473.823 | 426.081 | 4854.793 | 5862.440 | 5735.074 | 5938.699 | 8560.856 |
| Int64 | SumKernelTraits_Args0 | 424.508 | 458.248 | 7804.575 | 8108.408 | 9181.086 | 8364.106 | 8701.155 |
| Int64 | SumKernelTraits_Args | 446.097 | 428.538 | 8386.279 | 9239.331 | 9198.798 | 8344.952 | 8673.715 |
| SByte | SumScalar | 1496.783 | 1403.348 | 1448.660 | 1239.277 | 1468.827 | 1415.139 | 1213.582 |
| SByte | Sum256_Bcl | 901.114 | 1022.223 | |||||
| SByte | Sum512_Bcl | 989.131 | ||||||
| SByte | SumTraits | 1476.771 | 1494.144 | 17086.314 | 24231.464 | 24097.622 | 30243.434 | 60885.250 |
| SByte | SumTraits_Args0 | 1392.158 | 1331.083 | 45038.802 | 50540.409 | 49090.081 | 46979.783 | 60672.985 |
| SByte | SumTraits_Args | 1389.074 | 1295.641 | 46794.997 | 51069.265 | 50078.249 | 46518.750 | 65261.554 |
| SByte | SumKernelTraits | 1476.637 | 1242.198 | 27650.933 | 32894.218 | 32711.664 | 39630.939 | 72350.167 |
| SByte | SumKernelTraits_Args0 | 1523.543 | 1440.011 | 44451.891 | 49973.813 | 51540.236 | 48754.502 | 72615.251 |
| SByte | SumKernelTraits_Args | 1395.106 | 1274.943 | 41001.996 | 50067.099 | 49654.805 | 45904.504 | 71412.964 |
Description.
- SumScalar: Use the scalar algorithm.
- Sum256_Bcl: Use BCL's 256-bit vector methods (
Vector256.Shuffle). - Sum512_Bcl: Use BCL's 512-bit vector methods (
Vector512.Shuffle). - SumTraits: Use the normal methods of this library (
Vectors.Shuffle). - SumTraits_Args0: Use this library's
Coresuffixed methods (Vectors.Shuffle_Args,Vectors.Shuffle_Core), without ValueTuple, use the "out" keyword to Returns multiple values. - SumTraits_Args: Use this library's
Coresuffixed methods (Vectors.Shuffle_Args,Vectors.Shuffle_Core), using ValueTuple. - SumKernelTraits: Use the normal methods of this library's YShuffleKernel (
Vectors.YShuffleKernel). - SumKernelTraits_Args0: Use the
Coresuffixed methods of this library's YShuffleKernel (Vectors.YShuffleKernel_Args,Vectors.YShuffleKernel_Core), without ValueTuple, use the "out" keyword to return multiple values. - SumKernelTraits_Args: Use the
Coresuffixed methods of this library's YShuffleKernel (Vectors.YShuffleKernel_Args,Vectors.YShuffleKernel_Core), using ValueTuple.
BCL's method (Vector.Shuffle) runs on X86 platforms without hardware acceleration for all number types.
This library replaces these types with efficient algorithms implemented by combinations of other instructions. As of .NET Core 3.0, hardware acceleration is available.
Methods using this library's Core suffix optimize performance by moving some operations out of the loop to be processed earlier. This is especially true for the Shuffle method.
YShuffleKernel can be used instead of Shuffle if you can ensure that the index is always in the valid range. It is faster.
For Args suffixed methods, in addition to returning multiple values with the "out" keyword, ValueTuple can be used to receive multiple values, simplifying the code. However, be aware that ValueTuple can sometimes slow down performance.
Shuffle - Arm - AWS Arm t4g.small
| Type | Method | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|
| Int16 | SumScalar | 427.276 | 421.887 | 421.454 | 526.589 | 516.294 |
| Int16 | Sum128_Bcl | 482.907 | 468.383 | |||
| Int16 | SumTraits | 428.281 | 4922.876 | 5555.655 | 5864.193 | 9711.569 |
| Int16 | SumTraits_Args0 | 428.928 | 7902.420 | 8416.624 | 9925.441 | 9709.555 |
| Int16 | SumTraits_Args | 405.537 | 2809.483 | 2798.925 | 9880.804 | 9707.490 |
| Int16 | SumKernelTraits | 427.637 | 5650.913 | 6540.446 | 7957.175 | 9833.813 |
| Int16 | SumKernelTraits_Args0 | 427.578 | 7897.224 | 7891.894 | 9929.863 | 9819.774 |
| Int16 | SumKernelTraits_Args | 405.223 | 2811.195 | 2797.170 | 9861.330 | 9829.822 |
| Int32 | SumScalar | 286.900 | 281.167 | 281.838 | 317.876 | 309.427 |
| Int32 | Sum128_Bcl | 304.320 | 301.222 | |||
| Int32 | SumTraits | 286.596 | 2311.209 | 2472.592 | 2917.343 | 4801.979 |
| Int32 | SumTraits_Args0 | 288.066 | 4185.430 | 3928.604 | 4934.590 | 4821.784 |
| Int32 | SumTraits_Args | 270.249 | 1396.323 | 1401.742 | 4886.669 | 4806.886 |
| Int32 | SumKernelTraits | 287.386 | 2677.394 | 3247.692 | 3953.573 | 4846.437 |
| Int32 | SumKernelTraits_Args0 | 286.724 | 3919.619 | 4182.617 | 4930.469 | 4852.808 |
| Int32 | SumKernelTraits_Args | 270.724 | 1399.968 | 1395.953 | 4899.359 | 4853.093 |
| Int64 | SumScalar | 448.592 | 440.758 | 444.884 | 552.061 | 534.531 |
| Int64 | Sum128_Bcl | 708.356 | 692.663 | |||
| Int64 | SumTraits | 190.913 | 1005.614 | 1064.650 | 1255.025 | 2448.365 |
| Int64 | SumTraits_Args0 | 426.809 | 2090.887 | 2100.527 | 2479.821 | 2451.574 |
| Int64 | SumTraits_Args | 179.534 | 698.013 | 699.200 | 2457.898 | 2451.414 |
| Int64 | SumKernelTraits | 448.065 | 1237.258 | 1412.876 | 1753.457 | 2434.096 |
| Int64 | SumKernelTraits_Args0 | 449.857 | 2101.411 | 1967.152 | 2469.054 | 2443.626 |
| Int64 | SumKernelTraits_Args | 345.877 | 701.805 | 698.753 | 2456.761 | 2451.680 |
| SByte | SumScalar | 665.739 | 664.224 | 658.168 | 834.224 | 803.566 |
| SByte | Sum128_Bcl | 647.757 | 610.244 | |||
| SByte | SumTraits | 680.590 | 13176.730 | 16739.161 | 19723.567 | 19531.685 |
| SByte | SumTraits_Args0 | 660.595 | 15704.393 | 15724.340 | 19723.852 | 19530.241 |
| SByte | SumTraits_Args | 637.568 | 5597.644 | 5602.803 | 19605.289 | 19527.338 |
| SByte | SumKernelTraits | 672.784 | 15604.597 | 16732.629 | 19692.571 | 19533.892 |
| SByte | SumKernelTraits_Args0 | 675.236 | 16718.959 | 15715.512 | 19729.144 | 19534.508 |
| SByte | SumKernelTraits_Args | 642.795 | 5573.999 | 5598.168 | 19588.655 | 19538.006 |
Description.
- SumScalar: Use the scalar algorithm.
- Sum128_Bcl: Use BCL methods (
Vector128.Shuffle). - SumTraits: Use the normal methods of this library (
Vectors.Shuffle). - SumTraits_Args0: Use this library's
Coresuffixed methods (Vectors.Shuffle_Args,Vectors.Shuffle_Core), without ValueTuple, use the "out" keyword to Returns multiple values. - SumTraits_Args: Use this library's
Coresuffixed methods (Vectors.Shuffle_Args,Vectors.Shuffle_Core), using ValueTuple. - SumKernelTraits: Use the normal methods of this library's YShuffleKernel (
Vectors.YShuffleKernel). - SumKernelTraits_Args0: Use the
Coresuffixed methods of this library's YShuffleKernel (Vectors.YShuffleKernel_Args,Vectors.YShuffleKernel_Core), without ValueTuple, use the "out" keyword to return multiple values. - SumKernelTraits_Args: Use the
Coresuffixed methods of this library's YShuffleKernel (Vectors.YShuffleKernel_Args,Vectors.YShuffleKernel_Core), using ValueTuple.
BCL's method (Vector.Shuffle) runs on the Arm platform without hardware acceleration for all number types.
This library replaces these types with efficient algorithms implemented by combinations of other instructions. As of .NET 5.0, hardware acceleration is available.
Note that prior to .NET 7.0, SumTraits_Args sometimes had a large performance difference from SumTraits_Args0, due to the large performance loss of ValueTuple under Arm.
YNarrowSaturate
YNarrowSaturate: Saturate narrows two Vector instances into one Vector .
YNarrowSaturate - X86 - AMD Ryzen 7 7840H
| Type | Method | .NET Framework | .NET Core 2.1 | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|---|---|
| Int16 | SumNarrow_If | 208.976 | 197.924 | 195.466 | 200.430 | 197.261 | 205.623 | 221.224 |
| Int16 | SumNarrow_MinMax | 200.034 | 201.184 | 197.505 | 208.715 | 199.736 | 222.635 | 208.102 |
| Int16 | SumNarrowVectorBase | 21160.119 | 19565.035 | 19063.346 | 19960.925 | 19532.398 | 19258.689 | 24197.090 |
| Int16 | SumNarrowVectorTraits | 20477.038 | 18251.731 | 44050.630 | 45196.128 | 43674.654 | 44677.389 | 47325.429 |
| Int32 | SumNarrow_If | 211.070 | 218.235 | 225.479 | 211.761 | 207.353 | 223.740 | 232.860 |
| Int32 | SumNarrow_MinMax | 221.396 | 206.735 | 214.815 | 214.341 | 211.238 | 210.944 | 223.415 |
| Int32 | SumNarrowVectorBase | 9753.258 | 9549.313 | 9743.042 | 9519.188 | 9577.993 | 10513.071 | 12059.829 |
| Int32 | SumNarrowVectorTraits | 9117.869 | 9253.891 | 20503.088 | 20225.447 | 19198.947 | 19012.815 | 19398.087 |
| Int64 | SumNarrow_If | 207.654 | 206.920 | 215.020 | 207.405 | 207.239 | 220.198 | 227.592 |
| Int64 | SumNarrow_MinMax | 205.724 | 201.036 | 203.815 | 200.292 | 213.422 | 213.819 | 231.741 |
| Int64 | SumNarrowVectorBase | 2951.264 | 2720.663 | 2835.882 | 2949.423 | 2915.473 | 4372.612 | 5917.536 |
| Int64 | SumNarrowVectorTraits | 2941.336 | 2696.543 | 4690.391 | 4875.851 | 4917.149 | 3808.744 | 9411.507 |
| UInt16 | SumNarrow_If | 1263.960 | 1205.876 | 1247.409 | 1184.537 | 1124.520 | 1175.733 | 1387.128 |
| UInt16 | SumNarrow_MinMax | 1363.298 | 1283.027 | 1336.103 | 1178.860 | 1344.978 | 761.908 | 1487.848 |
| UInt16 | SumNarrowVectorBase | 25617.831 | 25358.182 | 25019.795 | 25056.656 | 26527.170 | 25337.769 | 30941.796 |
| UInt16 | SumNarrowVectorTraits | 24795.433 | 24950.279 | 33163.801 | 41303.846 | 40678.067 | 29966.481 | 45560.104 |
| UInt32 | SumNarrow_If | 1446.297 | 1396.148 | 1364.953 | 1339.805 | 1382.470 | 1240.158 | 1507.078 |
| UInt32 | SumNarrow_MinMax | 1461.884 | 1346.542 | 1363.853 | 1376.390 | 1373.016 | 960.104 | 1383.498 |
| UInt32 | SumNarrowVectorBase | 12509.780 | 11160.711 | 11971.259 | 11511.978 | 11080.158 | 11897.237 | 15997.508 |
| UInt32 | SumNarrowVectorTraits | 12962.030 | 11581.014 | 14895.009 | 16343.372 | 17051.602 | 14727.107 | 19760.603 |
| UInt64 | SumNarrow_If | 1003.570 | 1326.642 | 913.881 | 912.071 | 878.848 | 1312.352 | 1874.180 |
| UInt64 | SumNarrow_MinMax | 1455.402 | 1404.391 | 1392.157 | 891.629 | 902.245 | 937.792 | 895.795 |
| UInt64 | SumNarrowVectorBase | 3340.377 | 3102.954 | 3033.044 | 3449.113 | 3649.422 | 5104.550 | 7693.314 |
| UInt64 | SumNarrowVectorTraits | 3306.018 | 3050.492 | 4497.385 | 5401.914 | 5969.621 | 4527.588 | 9530.757 |
Description.
- SumNarrow_If: Use scalar algorithm based on if statements.
- SumNarrow_MinMax: Use scalar algorithm based on the Min/Max methods of the Math class.
- SumNarrowVectorBase: Use this library's base method (
VectorTraitsBase.Statics.YNarrowSaturate). It is implemented by combining vector methods using BCL, and can take advantage of hardware acceleration. - SumNarrowVectorTraits: Use this library's traits method (
Vectors.YNarrowSaturate). It is implemented as an intrinsic function, allowing for better hardware acceleration.
For 16-32 bit integers, SumNarrowVectorTraits are much better than SumNarrowVectorBase after .NET Core 3.1. This is because X86 provides specialized instructions.
For 64-bit integers (Int64/UInt64), X86 does not provide an equivalent instruction. However, the SumNarrowVectorTraits version of the code uses a better intrinsic function algorithm, so it still outperforms SumNarrowVectorBase in many cases.
YNarrowSaturate - Arm - AWS Arm t4g.small
| Type | Method | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|
| Int16 | SumNarrow_If | 157.270 | 154.692 | 157.383 | 181.610 | 193.265 |
| Int16 | SumNarrow_MinMax | 160.909 | 165.733 | 108.425 | 184.240 | 189.973 |
| Int16 | SumNarrowVectorBase | 6100.275 | 6193.938 | 6308.118 | 7201.735 | 8261.974 |
| Int16 | SumNarrowVectorTraits | 6102.238 | 13460.358 | 13445.824 | 15514.261 | 13674.647 |
| Int32 | SumNarrow_If | 163.854 | 165.352 | 165.160 | 190.240 | 213.807 |
| Int32 | SumNarrow_MinMax | 154.976 | 162.019 | 161.884 | 195.349 | 194.881 |
| Int32 | SumNarrowVectorBase | 3047.923 | 3268.933 | 3253.378 | 3532.128 | 4034.752 |
| Int32 | SumNarrowVectorTraits | 3125.498 | 6121.553 | 6162.533 | 7914.641 | 6782.358 |
| Int64 | SumNarrow_If | 161.788 | 160.690 | 161.656 | 203.670 | 190.163 |
| Int64 | SumNarrow_MinMax | 160.836 | 157.655 | 164.693 | 194.496 | 201.793 |
| Int64 | SumNarrowVectorBase | 728.629 | 1157.104 | 1139.372 | 1231.877 | 1326.584 |
| Int64 | SumNarrowVectorTraits | 727.603 | 3114.720 | 3307.205 | 4088.677 | 3409.341 |
| UInt16 | SumNarrow_If | 527.761 | 515.076 | 531.818 | 608.056 | 832.441 |
| UInt16 | SumNarrow_MinMax | 573.087 | 525.410 | 576.628 | 608.744 | 893.594 |
| UInt16 | SumNarrowVectorBase | 8361.120 | 8439.577 | 7945.486 | 8853.731 | 11829.808 |
| UInt16 | SumNarrowVectorTraits | 8307.680 | 13106.613 | 14179.297 | 13964.213 | 16532.648 |
| UInt32 | SumNarrow_If | 537.550 | 534.718 | 539.467 | 620.874 | 989.646 |
| UInt32 | SumNarrow_MinMax | 539.997 | 537.029 | 545.333 | 620.923 | 827.472 |
| UInt32 | SumNarrowVectorBase | 4099.703 | 4021.154 | 3963.463 | 4356.804 | 5896.924 |
| UInt32 | SumNarrowVectorTraits | 4024.310 | 6340.994 | 6977.151 | 6619.009 | 7993.300 |
| UInt64 | SumNarrow_If | 619.788 | 621.120 | 620.256 | 827.649 | 995.113 |
| UInt64 | SumNarrow_MinMax | 619.494 | 620.151 | 620.119 | 818.259 | 994.695 |
| UInt64 | SumNarrowVectorBase | 1229.723 | 1821.232 | 1848.632 | 1805.499 | 2169.309 |
| UInt64 | SumNarrowVectorTraits | 1228.911 | 3489.303 | 3526.548 | 3480.212 | 4100.727 |
Description.
- SumNarrow_If: Use scalar algorithm based on if statements.
- SumNarrow_MinMax: Use scalar algorithm based on the Min/Max methods of the Math class.
- SumNarrowVectorBase: Use this library's base method (
VectorTraitsBase.Statics.YNarrowSaturate). It is implemented by combining vector methods using BCL, and can take advantage of hardware acceleration. - SumNarrowVectorTraits: Use this library's traits method (
Vectors.YNarrowSaturate). It is implemented as an intrinsic function, allowing for better hardware acceleration.
Since .NET 5.0, the Arm intrinsic function is provided. Therefore, starting from NET 5.0, SumNarrowVectorTraits are much more powerful than SumNarrowVectorBase.
YGroup3Unzip
YGroup3Unzip: De-Interleave 3-element groups into 3 vectors. It converts the 3-element groups AoS to SoA. It can also deinterleave packed RGB pixel data into R,G,B planar data.
YGroup3UnzipX2: De-Interleave 3-element groups into 3 vectors and process 2x data.
YGroup3Unzip - X86 - AMD Ryzen 7 7840H
| Type | Method | .NET Framework | .NET Core 2.1 | .NET Core 3.1 | .NET 5.0 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|---|---|---|
| Byte | SumBase_Basic | 255.172 | 496.713 | 501.725 | 499.601 | 566.925 | 505.052 | 670.702 |
| Byte | SumBase | 1140.616 | 1053.352 | 1089.103 | 1138.235 | 1111.114 | 1478.675 | 1463.708 |
| Byte | SumTraits | 1121.904 | 1086.799 | 7468.216 | 11280.246 | 11541.671 | 12438.171 | 21865.365 |
| Byte | SumX2Base | 2169.025 | 2088.353 | 2171.143 | 2111.332 | 2179.099 | 2812.575 | 2973.122 |
| Byte | SumX2Traits | 2229.977 | 2160.516 | 10419.951 | 10989.673 | 10985.330 | 11472.251 | 22393.695 |
| Int16 | SumBase_Basic | 213.465 | 389.617 | 439.760 | 352.833 | 453.870 | 404.842 | 533.252 |
| Int16 | SumBase | 738.972 | 723.809 | 686.669 | 739.079 | 728.061 | 1015.709 | 1008.942 |
| Int16 | SumTraits | 759.109 | 691.273 | 3767.055 | 5383.595 | 5638.094 | 6270.971 | 10452.168 |
| Int16 | SumX2Base | 1327.217 | 1262.400 | 1260.547 | 1312.866 | 1288.727 | 1723.543 | 1761.102 |
| Int16 | SumX2Traits | 1320.545 | 1227.530 | 6120.175 | 6190.444 | 6208.993 | 5798.718 | 10909.299 |
| Int32 | SumBase_Basic | 186.128 | 276.261 | 295.992 | 219.993 | 323.416 | 280.863 | 391.511 |
| Int32 | SumBase | 184.001 | 273.403 | 306.846 | 224.431 | 320.332 | 551.148 | 555.068 |
| Int32 | SumTraits | 189.108 | 277.059 | 6262.687 | 6454.641 | 6392.289 | 6488.127 | 6951.683 |
| Int32 | SumX2Base | 155.218 | 257.316 | 284.894 | 247.659 | 318.492 | 1072.598 | 1093.091 |
| Int32 | SumX2Traits | 160.252 | 253.319 | 5049.720 | 6341.390 | 6285.681 | 6215.097 | 7422.183 |
| Int64 | SumBase_Basic | 136.976 | 170.057 | 187.362 | 131.130 | 193.633 | 175.953 | 240.232 |
| Int64 | SumBase | 135.652 | 170.323 | 187.933 | 125.485 | 192.634 | 168.300 | 238.422 |
| Int64 | SumTraits | 135.704 | 167.900 | 4095.410 | 3868.199 | 4015.411 | 4061.920 | 4385.505 |
| Int64 | SumX2Base | 108.319 | 151.252 | 178.444 | 137.145 | 182.990 | 155.501 | 243.663 |
| Int64 | SumX2Traits | 109.441 | 151.243 | 2684.613 | 3883.237 | 3978.648 | 3893.358 | 4785.675 |
Description.
- SumBase_Basic: Use scalar algorithm.
- SumNarrowVectorBase: Use this library's base method (
VectorTraitsBase.Statics.YGroup3Unzip). It is implemented by combining vector methods using BCL, and can take advantage of hardware acceleration. - SumNarrowVectorTraits: Use this library's traits method (
Vectors.YGroup3Unzip). It is implemented as an intrinsic function, allowing for better hardware acceleration. - SumX2Base: Use
VectorTraitsBase.Statics.YGroup3UnzipX2. For 8~16 bit integers, YGroup3UnzipX2 is generally faster than YGroup3Unzip, more so under earlier versions of .NET. - SumX2Traits: Use
Vectors.YGroup3UnzipX2.
YGroup3Unzip - Arm - AWS Arm t4g.small
| Type | Method | .NET Core 3.1 | .NET 6.0 | .NET 7.0 | .NET 8.0 |
|---|---|---|---|---|---|
| Byte | SumBase_Basic | 263.957 | 265.524 | 327.819 | 381.159 |
| Byte | SumBase | 380.369 | 406.259 | 430.545 | 443.813 |
| Byte | SumTraits | 378.710 | 4381.575 | 4113.304 | 6510.157 |
| Byte | SumX2Base | 702.851 | 728.691 | 740.690 | 767.491 |
| Byte | SumX2Traits | 700.539 | 4412.785 | 4273.763 | 5294.112 |
| Int16 | SumBase_Basic | 188.885 | 189.823 | 222.856 | 279.398 |
| Int16 | SumBase | 213.360 | 228.410 | 235.157 | 242.377 |
| Int16 | SumTraits | 213.356 | 1926.559 | 2134.925 | 3037.124 |
| Int16 | SumX2Base | 419.434 | 448.638 | 466.043 | 475.565 |
| Int16 | SumX2Traits | 419.442 | 2413.794 | 2650.031 | 2638.161 |
| Int32 | SumBase_Basic | 138.088 | 143.089 | 154.241 | 196.818 |
| Int32 | SumBase | 141.071 | 143.390 | 186.784 | 198.177 |
| Int32 | SumTraits | 144.696 | 1033.899 | 1069.974 | 1494.205 |
| Int32 | SumX2Base | 121.726 | 138.986 | 275.479 | 310.983 |
| Int32 | SumX2Traits | 119.468 | 1598.185 | 1547.795 | 1618.239 |
| Int64 | SumBase_Basic | 109.766 | 100.523 | 84.039 | 189.270 |
| Int64 | SumBase | 109.531 | 102.084 | 81.358 | 185.056 |
| Int64 | SumTraits | 107.335 | 1153.333 | 1176.315 | 1191.362 |
| Int64 | SumX2Base | 97.857 | 96.111 | 79.729 | 203.008 |
| Int64 | SumX2Traits | 98.162 | 1216.716 | 1155.302 | 1374.619 |
More results
See: BenchmarkResults
Documentation
- Traits method list: TraitsMethodList
- Online document: https://zyl910.github.io/VectorTraits_doc/
- DocFX: Run
docfx_serve.bat. Then browse http://localhost:8080/ . - Doxygen: Run the Doxywizard and click File ->Open on the menu bar. Select the
Doxyfilefile and click "OK". Click on the "Run" tab and click on the "Run doxygen" button. It will generate documents in the "doc_gen" folder.
ChangeLog
Full list: ChangeLog